Summary
An effective way to learn a language is to observe its use in everyday life. Dr. John Lee applies computational methods to transform raw language data, harvested from the media and the classroom, into pedagogical material for language learning. Already shown to be effective in a number of user studies, this approach helps students to learn a language from everyday, authentic examples. This project received a Certificate of Merit in the Excellence in Knowledge Transfer Award 2016.
Project Descriptions
(I) Learning Cantonese with television subtitles
Dr. Lee constructed a corpus of aligned Cantonese and Mandarin sentences (Lee, 2011). This parallel corpus contains transcripts of Cantonese speech and the corresponding Mandarin subtitles, taken from a number of Cantonese TV shows, including news, dramas and talk shows (Figure 1).
Between 2012 and 2014, Dr. Lee and his colleagues deployed this corpus in the course “Cantonese Communication Skills for Putonghua Speakers” at CityU. Through a web-based interface, students learned Cantonese vocabulary by searching and browsing authentic examples as spoken on TV (Figure 2). This independent, data-driven learning activity resulted in significant improvement in the students’ knowledge of Cantonese vocabulary (Wong and Lee, 2016).
(II) Learning English with student essays
Learners of the same mother tongue often make similar mistakes in a foreign language. To capture general problems in English writing by Chinese speakers, Dr. Lee and Prof. Jonathan Webster built a corpus of English essay drafts written by students at CityU (Lee et al., 2015). English language tutors marked the grammatical errors in these essays.
Dr. Lee exploited statistics from this corpus to create a mobile app that provides language learning exercises. The app uses public-domain sentences from Wikipedia to generate multiple-choice questions for teaching English grammar, for example preposition usage (Figure 3). To create challenging questions for Chinese learners, the app identifies the most common errors in the essay corpus. Further, the app remembers a user’s mistakes, and pulls up similar questions when the user next logs in. These personalized exercises helped users better master preposition usage both in the short and long term (Lee et al., 2016).
References
Lee, J (2011). Toward a Parallel Corpus of Spoken Cantonese and Written Chinese. In Proc. 5th International Joint Conference on Natural Language Processing (IJCNLP).
Lee, J, Sturgeon, D, & Luo, M (2016). A CALL System for Learning Preposition Usage. In Proc. Association for Computational Linguistics (ACL).
Lee, J, Yeung, C Y, Zeldes, A, Reznicek, M, Lüdeling, A, & Webster, J (2015). CityU corpus of essay drafts of English language learners: a corpus of textual revision in second language writing. In Language Resources and Evaluation 49(3):659-683.
Wong, T S, & Lee, J. (2016). Corpus-based Learning of Cantonese for Mandarin Speakers. ReCALL. 28(2):187-206.

Figure 1. The Cantonese-Mandarin parallel corpus
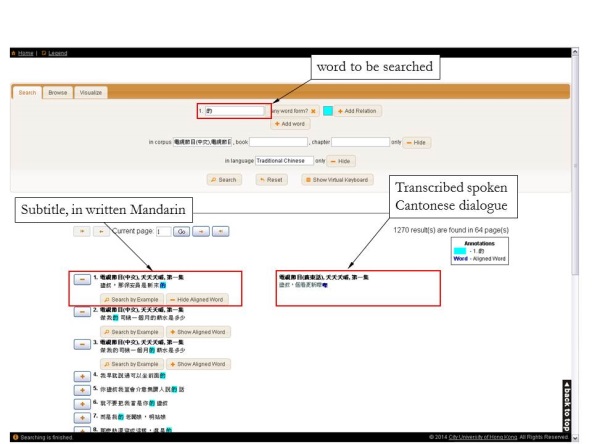

Figure 2. Search interface for the Cantonese-Mandarin parallel corpus, accessible at http://www4.lt.cityu.edu.hk/~yingchui/corpusSearch
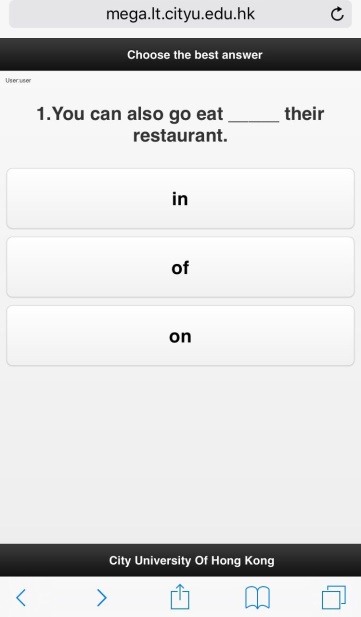
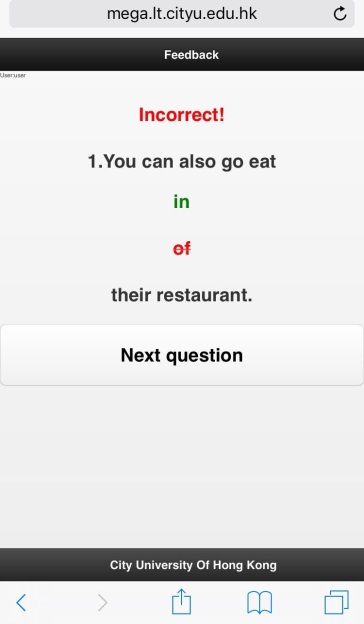
Figure 3. Interface of mobile app for learning English, accessible at
http://mega.lt.cityu.edu.hk/mengqluo.
